后端弟弟认识的zookeeper
前言#
第一次听说zookeeper,是activeMQ和kafka里的一个任务调度协调中心。
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。(via百度百科)
角色#
从简介看得出,zk的功能是维持一个分布式集群的秩序的存在,在zk的模型里,有三种角色「Leader」「Follower」「Observer」。
一个Leader为整个任务调度中心的管理者,负责整个zk中心的管理、决策、状态储存.
一个Follower就是一个普通的子节点,负责zk中主要业务的操作,包括接受数据,处理数据,处理由leader发起的事务(投票)。
Observer其实可以理解为是一个follower的slave节点,可以接收数据,处理数据的任务将转发给leader,无法进行事务的处理,本质上是为了提高整个zk中心的数据处理速度。

状态#
当一个非单节点zk由我们的配置文件启动时,会进入初始化选举leader流程。每个非observer节点会进入looking状态,可以以自身为主发起一个选举请求并全域广播,每个节点负责统计自己选举的票数,当票数过半时当选,当选后执行leader功能更新状态为leading/following并全域广播。
所有的非leader节点会定时向leader发送心跳包以维持连接和确认leader的运行状态。
如果此时leader挂掉或者由于连接过多阻塞了其他连接,无法接受心跳包的时候,所有节点会重新进入looking状态发起选举,但只有空闲状态下的节点能够发起选举(下面会解释空闲)。此时选举只有超过半票才能够当选(以保证大部分节点和主节点丢失连接而非偶然),当新节点上任后,同样会进行全域广播更新状态,但之后还会进行数据更新,向全域各个节点广播自己最大的zxid(事务id,用于区分事务先后),由其他节点来选择更新或者回退数据。
CAP原理#
Consistency一致性,Availability可用性,Partition tolerance分区耐受性。一般而言,CA之间不能同时成立,即在分布式架构中,无法同时保证整个系统的高可用性和强一致性。在满足一致性的前提下,系统读写过程需要加锁或者添加事件id,这时便会降低整个系统的效率或者产生冗余的数据。如果优先,满足高可用性,那势必不能对资源进行加锁操作,从而不满足强一致性。
以上的说法是在满足分区在P原则的前提下进行的,zk对每个节点采用数据拷贝的模式,即所有的数据节点的数据都是相同的
数据改动更新#
在zk中,CAP的类似实现成为ZAB协议(Zookeeper Atomic Broadcast原子广播协议)
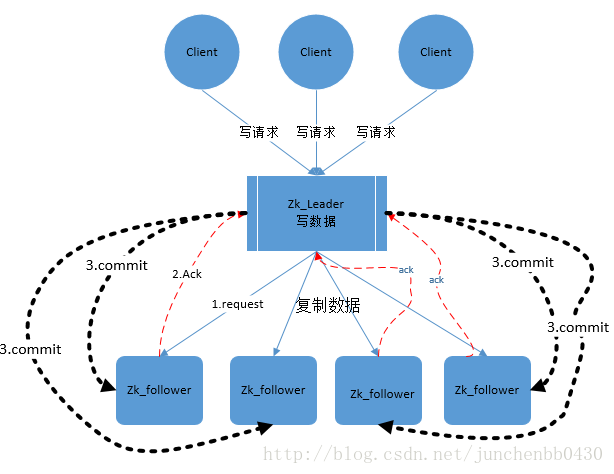
当有客户端连接到对外提供服务的节点并传入修改请求时,非leader节点会将请求转发给leader节点,收到请求后leader会发起一个全局提议并全局广播给所有follower节点(observer节点无投票权),其中,leader和follower之间的通信也是通过消息队列进行的,所以由leader发起的所有提起都是自带顺序的。follower节点从队列中拿出提议并通过向leader节点发送ack确认请求表示确认该次提议,或在本地直接标记为丢弃该请求。当leader受到超过半数的ack确认后立即对该提议进行commit写入数据,然后向全局所有节点发送commit通知更新请求
- 当一个提议提出但还未提交的时候leader宕机
开始选举流程,参与选举的节点必须为空闲的follower,即没有未处理(分发/确认/丢弃)的提议,若此时原leader节点恢复工作,它将加入follower阵营中,由于它宕机前的提议尚未处理完成,他将没有参选资格。选举完成后,leader必定不是原leader,所以原leader的提议将会回退,本次修改请求失效。
- 当一个提议被提交后leader宕机
开始选举流程,若此时leader恢复,他有资格参与选举,选举完成后由于提议commit已经分发,本次修改请求有效,对外界无影响。
- 当收到一个修改请求但为提出提议时leader宕机
开始选举流程,原leader有未处理请求,即使恢复也无法参选,由于未分发,选举完成它本身必产生回退,本次修改请求失效。